

Olá pessoal!
Hoje vou ensiná-los como instalar o Pyspark no seu computador com sistema operacional Windows!😁
Instalação do Pyspark, JDK e Hadoop
- Primeiro de tudo, o que você vai precisar é ter o Python instalado na sua máquina. Caso você ainda não tenha o Python instalado, favor verificar o post 😊
2. Vá no “Menu Iniciar” e digite “Prompt de Comando” e abra o aplicativo.
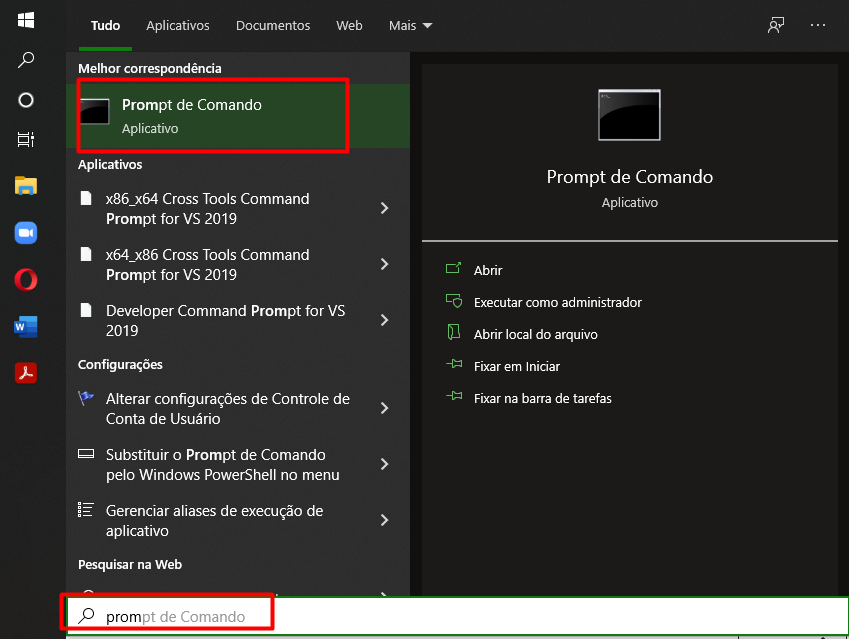
3. Digite o seguinte comando no Prompt:
pip install pysparkCom isso, a biblioteca do Pyspark já estará instalada no seu computador e pronta para ser usada no seu Python 🐍
4. Será necessário instalar o Java Development Kit. No próprio site do Java você pode encontrar várias versões.
5. No caso do Windows, para que você consiga configurar também o uso do Hadoop, você deverá acessar este link e selecionar a versão de interesse.
6. Após baixado o arquivo do item 5, coloque o seu conteúdo extraído do Hadoop no diretório de instalação da biblioteca Pyspark. Você consegue verificar aonde seu Python está instalado a partir do código:
import os
import sys
os.path.dirname(sys.executable)Usualmente a biblioteca estará instalada em “[sua_localização_do_Python]/Lib/site-packages/pyspark”.
Configuração das variáveis de ambiente do sistema
Para que o Spark funcione sem problemas é necessário também adicionar variáveis de sistema.
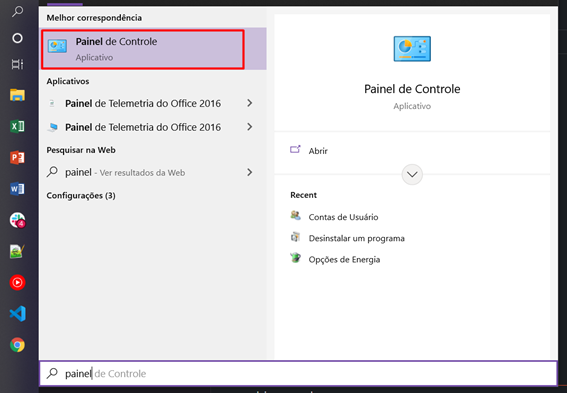
- Entre no menu do Windows e pesquise por “Painel de Controle”, como na imagem abaixo:
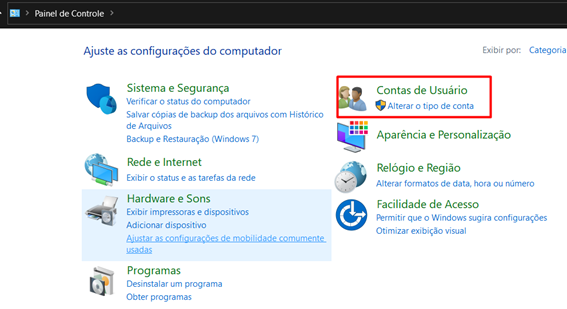
2. Já no “Painel de Controle”, abra o item “Contas de Usuário”:
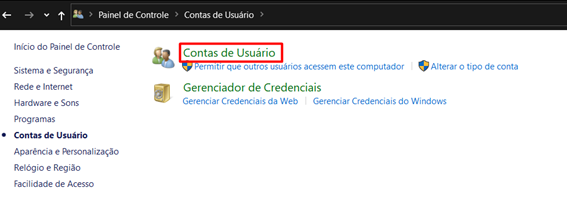
3. Clicar novamente em “Contas de Usuário”:
4. Clicar em “Alterar as variáveis do meu ambiente”:
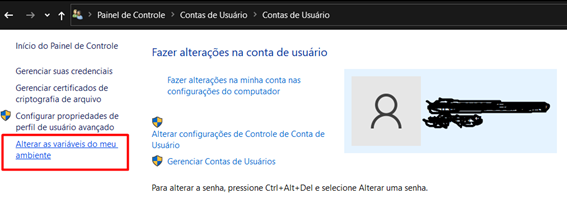
5. Aqui, uma nova caixa de diálogo irá aparecer com as variáveis de usuário e as variáveis de sistema, você irá fazer a alteração nas variáveis de sistema (segundo bloco destacado na imagem).
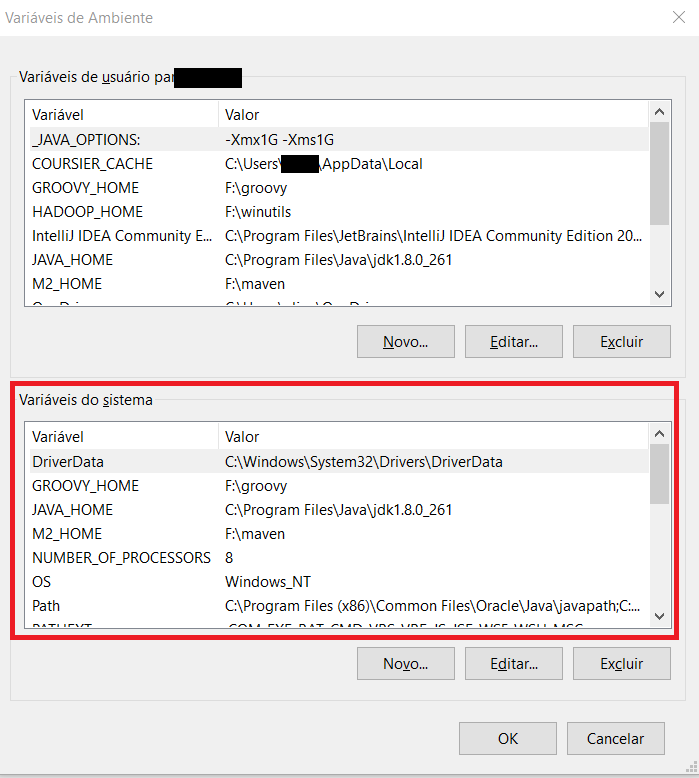
6. Clicar no botão “Novo”, uma nova janela será aberta.

7. Na nova janela criar as seguintes variáveis:
- SPARK_HOME = “[sua_localização_do_Python]\Lib\site-packages\pyspark” -> este é um exemplo de caminho, basta você direcionar essa variável para o diretório onde sua biblioteca está instalada
- HADOOP_HOME = “[sua_localização_do_Python]\Lib\site-packages\pyspark\hadoop-[versão]” -> este é um exemplo de caminho, basta você direcionar essa variável para o diretório onde seu Hadoop foi extraído
- JAVA_HOME = “C:\Program Files\Java\jdk[versão]”-> este é um exemplo de caminho, basta você direcionar essa variável para o diretório onde seu JDK foi instalado.
Após fazer as edições, clicar em “Ok” e as variáveis estarão configuradas 😁
Com isso, você terá o Pyspark configurado e já conseguirá fazer seus primeiros códigos para trabalhar com Big Data 😃




